
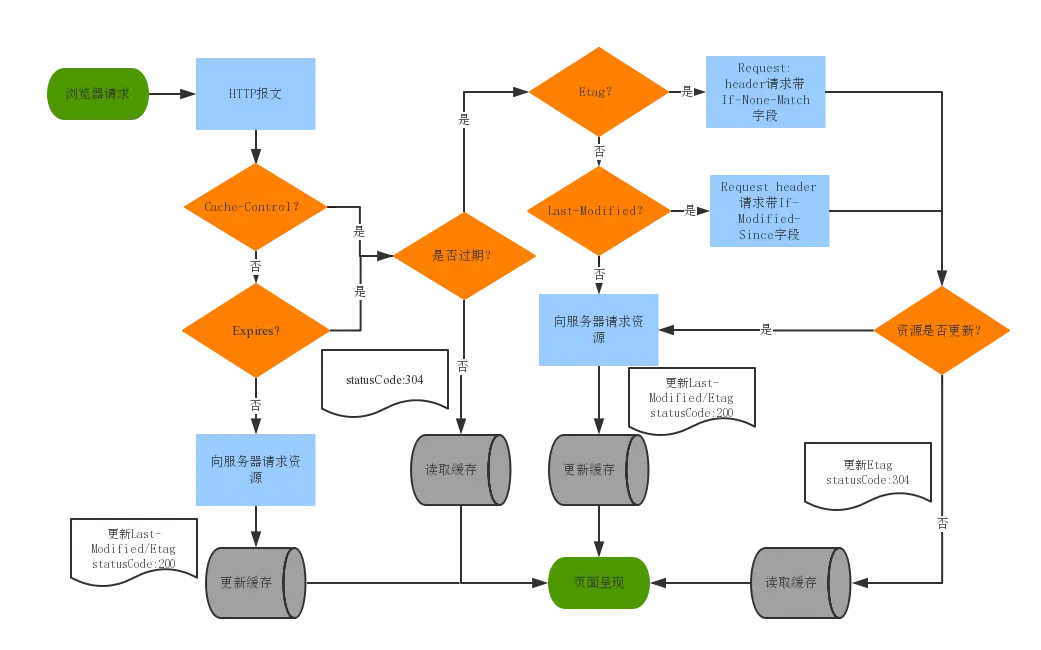
友情提示:缓存什么的,是完全依赖相关http header头信息来标记和判断的
缓存读取顺序:
首先读取本地缓存,如果条件满足就取本地缓存,否则往后走代理缓存,同理,条件满足就是从代理缓存取资源(可能存在多级代理缓存)
如果一条链路上的资源都不符合,那么就去源服务器获取
缓存优先级:Cache-Control > Expires > Etag > Last-Modified
缓存的分类和优先级
- 强缓存 状态码 200 (比如 200 (from cache))
- Expires 服务器下发的绝对时间,而判断的时候以浏览器时间为准,客户端和服务器有可能会不一样
- Cache-Control 相对时间,以客户端相对时间为准
- 协商缓存 状态码 304
- Last-Modified If-Modified-Since
- Etag If-None-Match
强缓存优先级高于协商缓存,强缓存不会询问服务器,直接使用缓存。协商缓存会询问服务器关于文件的可用性
对于传输过程中的中间节点,本文都称为代理服务器,包括proxy、CDN和缓存服务器
缓存头Cache-Control
可缓存性 (哪些节点可以进行缓存)
- public 在这个请求的返回过程中的任何节点都可以对这个返回的内容进行缓存,比如代理服务器可以对其缓存
- private 只有发起请求的节点才能进行缓存,其他节点都禁止缓存资源
- no-cache 可以进行缓存,但是在使用之前,要去服务器先验证缓存的有效性,有效的话才能使用,搭配max-age=0使用,不会直接从浏览器读取相应的缓存文件,而是先向服务端发起请求确认浏览器的缓存是否过期来判断是从浏览器加载还是从服务器加载
- no-store 任何节点都不能进行缓存
到期时间
- max-age = 多少秒之后缓存内容过期
- s-maxage = 只在代理服务器生效。优先级大于max-age。如果s-maxage时间到了,代理服务器会去远端读取新的数据并更新缓存
- max-stale = 即便缓存过期了,只要在max-stale的范围,则不需要请求新的缓存
重新验证
- must-revalidate 在设置了max-age过期之后,浏览器必须去源服务端获取新的数据
- proxy-revalidate 代理服务器数据过期后,必须去源服务端获取新的数据
其他
- no-transform 用在代理服务器,不允许对返回内容进行压缩、格式转换等
上述头信息是规范,但是很多代理服务器不按这个来
缺点:Cache-Control为客户端缓存,服务端更新了文件之后,客户端并不第一时间更新缓存,这也是web开发中的常见问题
Cache-Control缺点的通用解决方案:在打包文件之后,根据静态文件内容加上一串hash码或者版本号,如果静态文件内容没变,则hash不会变,反之,静态文件内容变化之后,hash码变化,则静态资源url发生变化,可以更新客户端缓存
举例
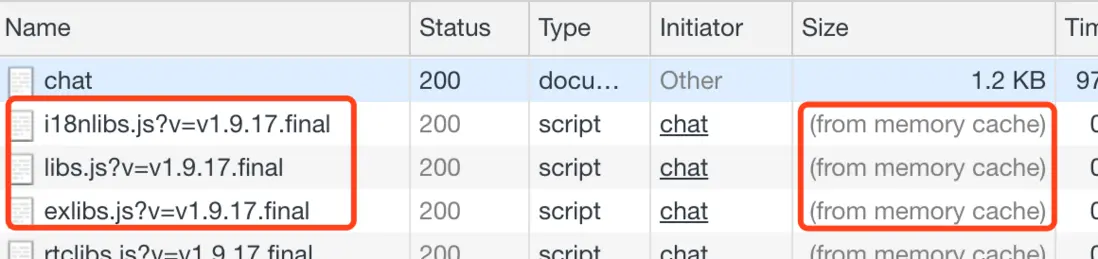
我司的处理:可以看到,devTools的Size栏,提示出from memory cache,即读取浏览器本地缓存
示例代码:这里是用模板来加载的,support来填充,猜测可以在初始化请求的时候,通过请求配置接口,拿到对应的web资源的版本号的接口或者配置文件,然后再静态资源去加载之前,将对应的版本号填充到对应的src或者link中
资源验证头信息Last-Modified和Etag
Last-Modified
资源上次修改时间,主要配合If-Modified-Since或者If-Unmodified-Since使用:如果请求了一个资源的respose header里面有Last-Modified头信息指定了一个时间,下一次浏览器发起请求的时候,通过If-Modified-Since或者If-Unmodified-Since(通常使用If-Modified-Since,If-Unmodified-Since很少用)带上那个时间,带到服务器,服务器读取并对比这个资源上次修改的时间,如果一致,则代表资源没有被修改过,那么浏览器可以继续使用缓存,反之缓存不能使用
ps:如果资源是存在数据库的,可以给资源加上一个update-at的字段加上修改时间作为Last-Modified时间返回给浏览器
Etag
更加严格的验证方式,通过数据签名的方式,根据资源的内容产生一个唯一的签名,如果资源的内容产生了修改,那么签名就会更新,任何的修改都会导致签名不一致,常用方式是对资源的内容进行hash计算产生签名来标记资源。
配合If-Match或者If-Non-Match使用,下一次浏览器发请求会带上If-Match或者If-Non-Match头,头里面的值就是服务端上一次给出的Etag签名,然后服务器对比签名是否一致
http code 304资源没有修改,可以直接读取缓存,及时这时候服务端有了新的返回,也会被浏览器忽略,直接读取缓存数据(写个接口,而不是静态资源文件来验证一下)
tips:
chrome的devTools,当把Disable cache勾选上之后,浏览器就不往服务器发送关于缓存的头信息了,这时候只能从服务器读取最新的数据
缓存对比localStorage: 缓存文件不用自己去控制localStorage的读写呢
本文是 18年我发布在 Segmentfault 社区的,时间过得真快









Discussion